2021年re:Invent,AWS在RDS多可用区实例的基础上,推出了RDS多可用区集群,并且在2022年2月GA,随着时间的推移一晃就是又一年多过去,亚马逊云科技终于在中国区域发布了这个功能,可见以下NEWS
https://www.amazonaws.cn/new/2023/amazon-rds-multi-az-db-cluster-launch-for-china-regions/
本文简单对比一下两种多可用区部署的不同,更多的讨论我们将在之后的文章中进行。
在很长一段时间内,AWS的RDS服务,提供的托管的MySQL/PgSQL提供的是一种叫做多可用区数据库实例的部署方式,这通常由一个Primary和一个Standby Replica组成,简单的结构如下
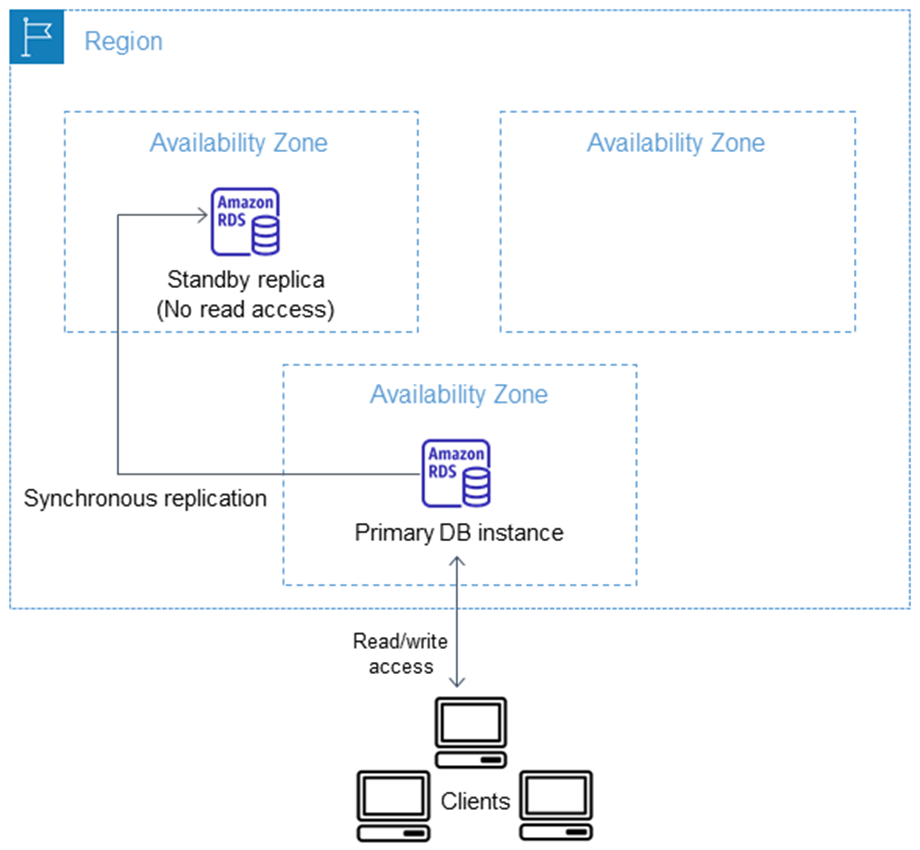
这里由几个点需要注意,首先Primary负担所有的读取和写入请求,在不同AZ的Replica只是Standby,它只用来做FO,并不承担读取流量,即冷备。但你仍需要为它付额外的费用,在这种场景下如果你还需要一个Replica来offload 读取请求,则你需要创建Read Replica。
多可用区数据库实例的部署,FO的时间通常在60-120s左右,但是Standby的Repica是同步的。
需要注意的是,多可用区数据库实例对数据库实例的类型没有任何要求。
而自2021年11月推出,2022年GA,2023年引入中国区域的多可用区部署,被叫做多可用区数据库集群,由三个实例组成,Replication不同于多可用区数据库实例,不需要所有的节点都确认才能确认,只需要有一个Reader确认即可。其结构如下图。
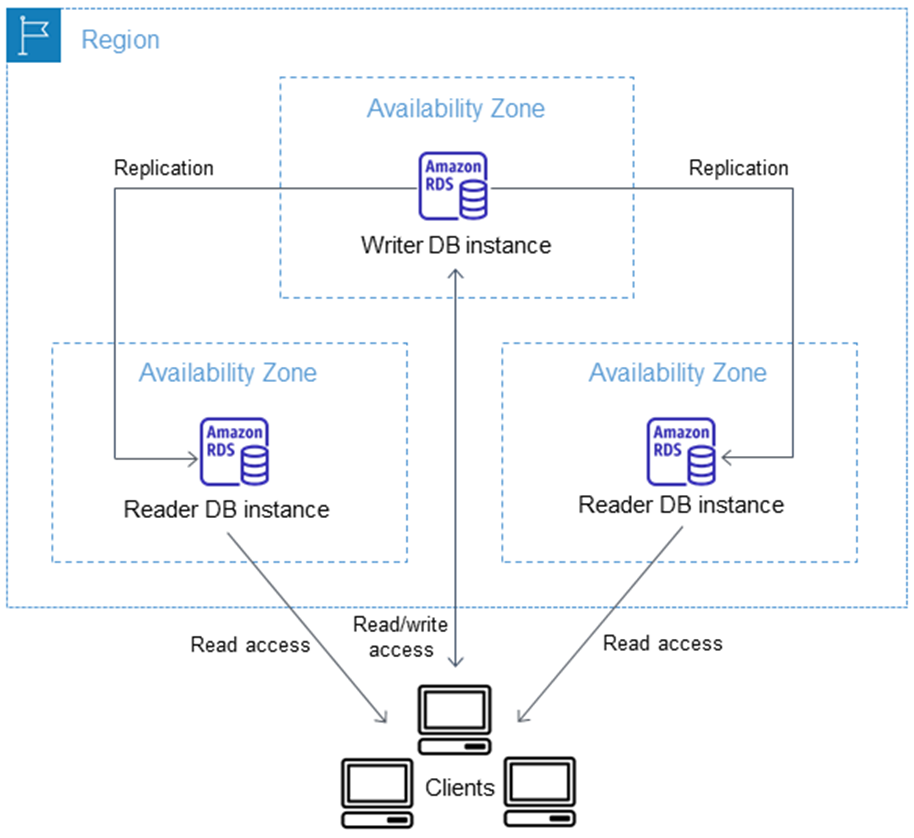
多可用区数据库集群,Reader节点是热备,所以可以承担读取流量,并且FO的时间典型值会缩短到35s以下。
需要注意的是,多可用区数据库集群利用了具有实例存储的实例类型,实例存储用来存储事务,而EBS作为永久存储。
所以多可用区数据库集群和实例相比,有以下几个优势:
1. 更快的写入性能,这利用了事务日志实例存储
2. 更快的故障转移,35s对比于之前的60-120s
3. Reader节点可以承载读取流量
4. 两个Reader只需要一个确认即可确认,优化了Replication
但是我们同时要注意到多可用区数据库集群也有一些限制,具体可以参考
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/multi-az-db-clusters-concepts.html
其实在接下来的5月14日,亚马逊云科技中国区域紧跟着Global推出了Optimized Reads,即下面这个
https://aws.amazon.com/cn/blogs/china/introducing-optimized-reads-for-amazon-rds-for-postgresql/
相关的文章也可以参考
https://aws.amazon.com/cn/blogs/china/introducing-optimized-reads-for-amazon-rds-for-postgresql/