DocumentDB (MongoDB兼容)发布于2019年1月,于2020年11月增加了MongoDB 4.0 API的支持,同时在2021年6月增加了Global Cluster的支持。
实际上AWS的这个产品也采用了存储与计算分离的设计,本质上还是和MongoDB不同的,只是在API上做到了部分兼容,在此次Elastic Clusters发布前,DocumentDB Clusters和Aurora一致,都需要选择对应的实例类型,而这些实例类型就固定了一定的性能,关于选择实例类型的最佳实践可以参考
https://docs.aws.amazon.com/documentdb/latest/developerguide/best_practices.html#best_practices-instance_sizing
同时也可以使用这个第三方工具来进行计算https://sizing.cloudnativedb.com/
值得注意的一点是,DocDB和无Sharding的MongoDB一样(当然也可以说DocDB不支持Sharding),其写入节点只有一个,再组合固定的实例类型,这就导致了DocDB的写入性能存在瓶颈。
而今年的reInvent,AWS则推出了自己的Sharding方案,同时也消除了实例类型这个变量,同时冠以一个很模糊的名字DocumentDB Elastic Clusters,目前可用的区域有限,我们来初探一下。
关于今年reInvent,DocDB的发布,大家也可以观看DAT-219来获得更多的信息。
https://www.youtube.com/watch?v=Eg0tJEAZVhU

可以看到在Elastic Cluster GA的区域中,创建Cluster的过程的第一步就是让你选择Cluster的Type
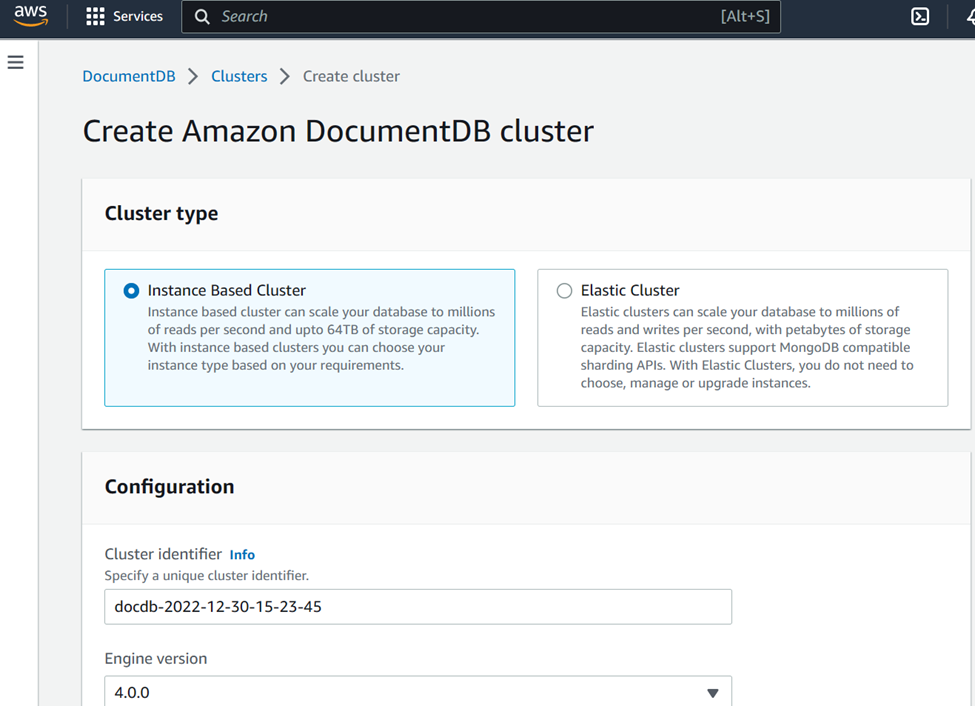
接下来则是选择shard的数量,以及每个shard的vCPU容量,这里已经可以看出并不是instance-based的了,你无法选择shard的实例的类型。
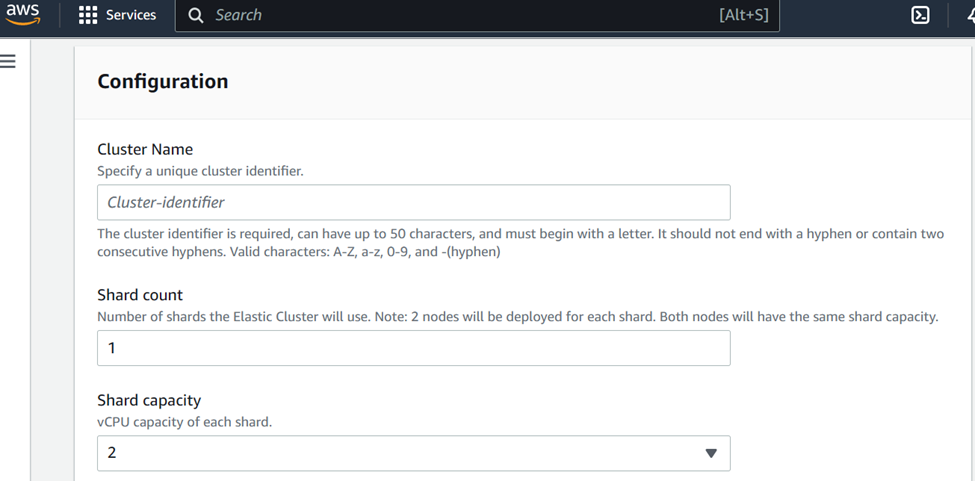
实际上创建过程就结束了,这里消弭了很多复杂度。
我们结合The Register的文章再来理解一下,Elastic Cluster借助MongoDB sharding API来创建分片的集合,让数据可以分布在多个shard里面,每个shard有其writer,这样实际上就扩展了读写的能力,而AWS在这个过程中实质上简化了集群的维护过程——如果你有MongoDB集群创建维护经验的话,你会清楚无Shard的MongoDB集群是简单的,但是一旦考虑Shard,那么集群的规模、node的升级维护都是一个非常棘手的问题,而AWS借助其控制平面来帮你处理这些所有的问题。这个思路我们也可以在今年发布的OpenSearch Serverless看出,两者都是极大程度上简化了集群的运维成本。
我们回到一个应用或者服务的实际的开发过程,这种简化了的Serverless服务,实际上提供了一种一开始就基于超大数量级开发的云应用可能。先前我们基于对数据库集群的维护的畏惧以及对够用就好的想法,导致了一开始选择了常规的数据库部署方式,等应用扩展到一定规模了,再来进行数据库的再设计,还增加了迁移的开销。实际上现代应用,或者基于云的现代应用再数据建模和数据库设计上已经有了充足的经验了,我们很乐意看到,All Serverless正在下沉到服务的基石——数据上。